

API Forking for an Adaptive Development Process
How we kept a stable application amid shifting client requirements.

At Sanctuary Computer, we devote teams of highly specialized developers to augment our clients’ product teams. This means some of our developers spend years working on early-stage technical projects, often concepting, launching and maintaining complex software and APIs for connected hardware products, mobile apps, and more.
Over the past few years, our embedded development teams have learned that fast iteration and the ability to navigate uncertainty are important skills to hone in this mode of working.
That said, it can be challenging to design a flexible API that maintains data integrity under these conditions.
Our team was building a mobile application and backing API for one of our clients when we faced this problem. The architecture was a simple 3-tier architecture with a mobile app, REST API and PostgreSQL DB:

At the beginning of the project, the implementation had users onboard by downloading and signing up through the mobile app. This presented friction and lower conversion so the team decided to migrate several pieces of functionality to the website, which presented a couple of constraints:
The website needed to rely on the same backend API and database as the mobile app.
The website and app needed consensus on the API contracts for overlapping features — but UX requirements for the website differed from the web app, with some fields being omitted entirely, newly added or combined in different ways.
The existing mobile app functionality needed to continue to work unbroken, but it was unclear whether some new planned features would be added simultaneously to the mobile app and website. We needed to account for the fact that they could.
What was certain was that the signup and account management functionality on mobile would eventually be deprecated in favor of the website. The website’s definition of the data would be canonical.
We finally needed to identify the desired outcomes and ground rules to avoid coding ourselves into a corner or introducing bugs. We had to ensure that each mobile app write would lead to a data state that was valid for both the mobile app and the website, and vice versa, as conflict commonly happens when there are two actors writing data to the same resource which impose different requirements.
Our approach
Our approach was inspired by the Parallel Change pattern. We first ensured there were separate namespaces on the API — web for the website and app for the mobile app — to segregate each client interface. All the original endpoints lived under app and we forked them to web, such that we had the existing GET /app/user forked into GET /web/user and so forth. This provided the same exact interface and we could now tweak it into supporting the new requirements for the website.
Next, we identified the different kinds of changes that could happen to this new interface, namely, destructive and additive changes.

Destructive changes
If an existing readable field was removed, renamed or had its type changed by the web interface, its data remained accessible to the app by the same field name and type. Since both interfaces were reading from the same datastore, it meant there had to be type conversions and data manipulation before returning the data.
e.g. web needed to split the singular user name field into a first and last name and we effected that in the datastore then concatenated the first and last name into name when returning it on the app interface.




If a writable field was removed by the web interface but was still required by the app during a mutation operation (create/update), the web interface needed to maintain that field and provide a dummy default value.
An existing field could also not be made nullable since that would equally violate the app contract.
e.g. if the
street_addressfield was removed from the user creation web interface but still needed on the app, the web interface would continue writing this field to the database but populate the column(s) with a dummy value.


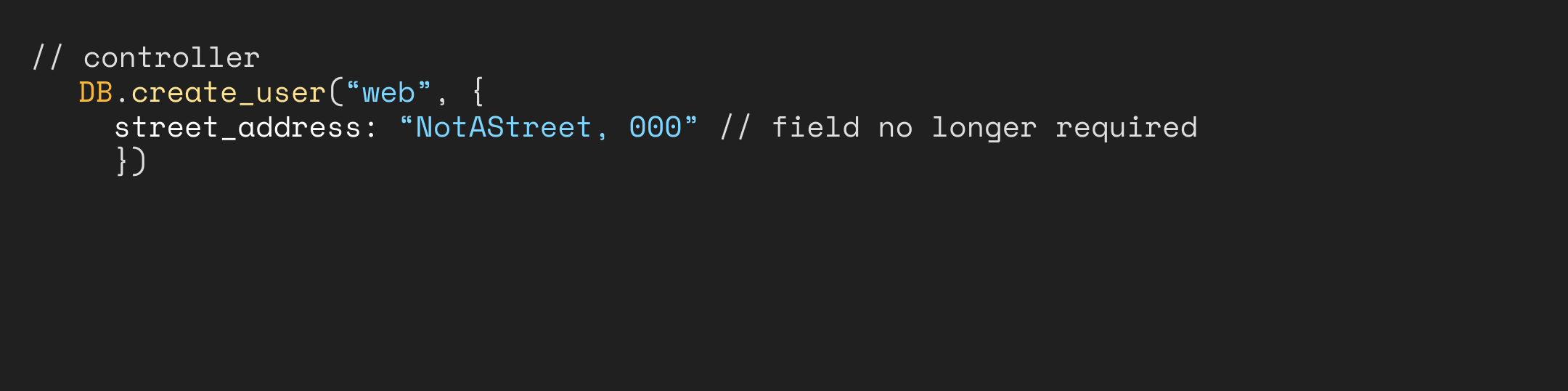
For both the above examples, the same rules would apply for destructive changes done on the app interface though we did not encounter this scenario.
Additive changes
Additive changes, where new fields or endpoints were added, were simple to plan around since clients can always ignore data fields and operations they aren't interested in.
The most important rule was to maintain parity in naming and types between overlapping fields on both interfaces to make it easier to re-merge the two interfaces later on.
Code structure
Since our API uses an MVC framework, we implemented this by having one model but separate controllers for web and app APIs.

Conclusion
These rules allowed us to rapidly migrate and iterate on the new website interface with close to zero bugs. After several months, the requirements had crystallized, the app didn’t replicate any functionality of the website besides login, and we were able to safely remerge the app and web API forks. This remerge kept in mind scenarios:
Where the web endpoints had removed fields from the interface — we dropped database columns and changed types where needed.
Where the two forks remained the same — we simply did away with the app side of the fork since web was canonical.
Where the features on both forks were deprecated — we got to delete the code entirely 🎉
Illustrations for this article were made by Lourenço Providencia.
Staff Augmentation at Sanctuary Computer
At Sanctuary, we do some of our best work in long-term engagements with start-ups. Working with emergent companies who may not have time to hire a team of best-in-class developers, we’re able to provide all of the skill and security of a full-time product team, with none of the risk that comes with hiring.
We currently have dedicated teams working on long-term engagements with The Light Phone and Mill.
Learn more about our embedded teaming model, or drop us a line at hello@sanctuary.computer.

 | A guest post by
|